I’ve recently discussed the notion of Analytics Engineering. But what are the tools that an Analytic Engineer must know to perform their duties? In this post, I will explore the must-haves for an Analytic Engineer.
A very clear image depicting the Analytics Engineering data flow can be found on the dbt website.
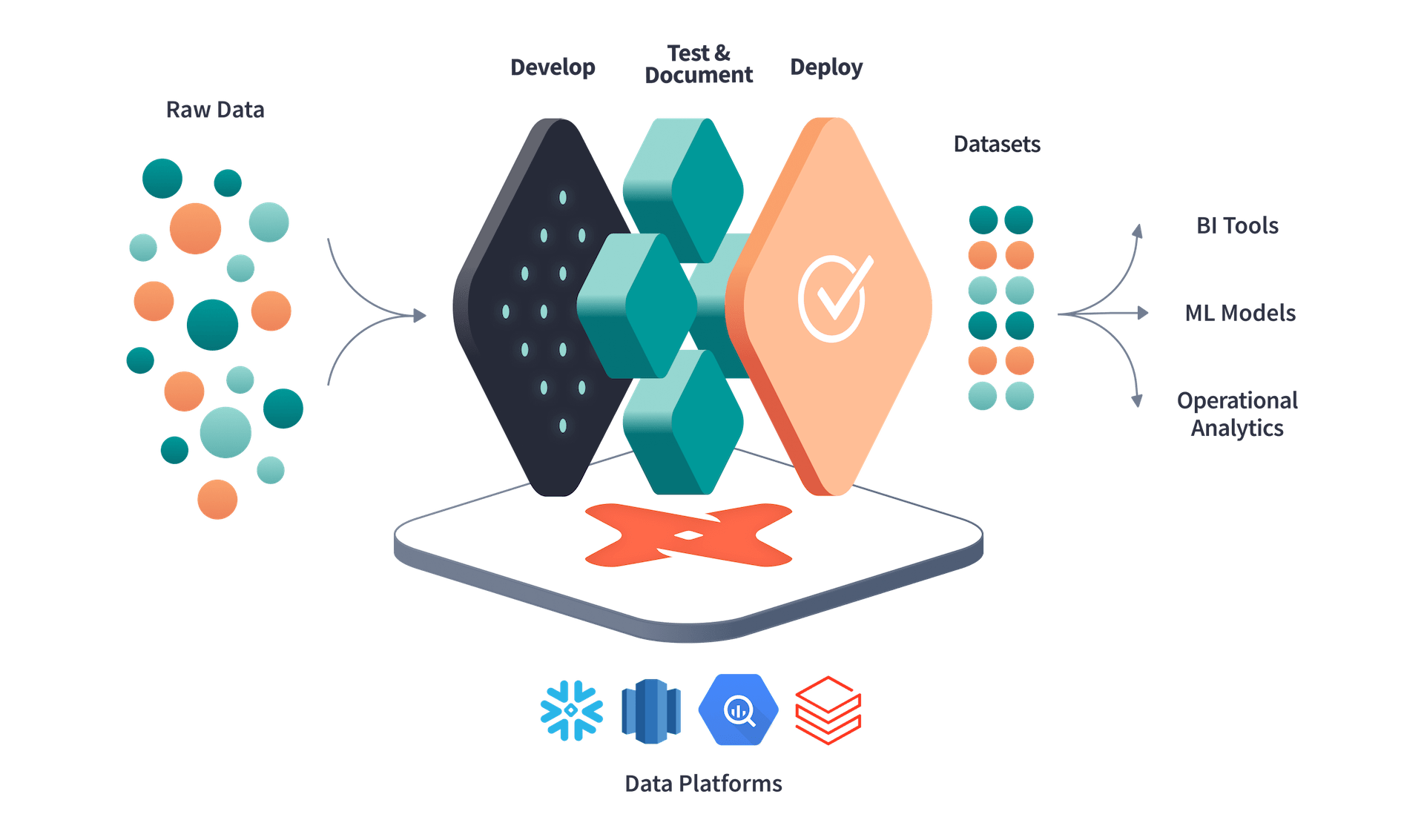 The data flow of Analytics engineering using dbt
The data flow of Analytics engineering using dbt
In this image, the transformation layer is carried out with the tool that the company proposes. However, this is not always the case, as there are multiple tools to transform raw data once inside the database. Nonetheless, I came across dbt last year, and the tool is extremely efficient and performs well, despite being relatively young.
But enough with the preface, let’s dive into the tech stack. I’ll give an overview of the tools used in the field, but then focus a bit more on dbt as a tool that could conquer the transformation layer in the future.”
Data Collection and Storage
The first step in the Analytics Engineering process is data collection. In my opinion, this is a step in the process where there should be co-ownership with the Data Engineering side (if the team is mature enough to allow for different roles). The initial pipeline that bridges the raw data sources (including web servers, mobile apps, IoT devices, and other third-party platforms) should have already been built using the classical Data Engineering stack (e.g., Python).
The data is stored directly in a data warehouse or data lake and is kept as close as possible to the original source (this is an assumption of the ELT approach, which implements data transformation after the loading stage). There are similar tools and infrastructures available regardless of the technology provider. For example:
a. Amazon S3 - A cloud-based storage solution that provides scalable and cost-effective storage for data. b. Google Cloud Storage - Similar to Amazon S3, this solution provides a scalable and cost-effective storage solution for data. c. Apache Hadoop - An open-source framework that allows for distributed processing and storage of large datasets.
Once the data resides in the storage layer, ownership shifts, and it becomes a pure Analytics Engineering responsibility to carry out the processing needed to bring value to the data consumers (Data Analysts/Scientists, Business owners).
Data Processing
After the data is collected and stored, the next step is data processing. This involves cleaning and transforming the data into a format that is suitable for analysis. Some of the popular tools used for data processing include:
Open source a. Apache Spark - An open-source big data processing engine that allows for distributed processing of large datasets.
b. Apache Kafka - A distributed streaming platform that allows for real-time processing of data.
c. Apache NiFi - An open-source data integration platform that allows for the automation of data flows between systems.
Microsoft Azure a. Azure Data Factory - A cloud-based data integration service that allows users to create, schedule, and manage data pipelines.
b. Azure Stream Analytics - A real-time data processing service that allows users to analyze streaming data from various sources, such as IoT devices and social media.
c. Azure Databricks - A collaborative Apache Spark-based analytics platform that allows users to perform big data processing and machine learning at scale.
Amazon Web Services (AWS) a. AWS Glue - A fully managed ETL service that makes it easy to move data between data stores.
b. Amazon Kinesis - A platform for streaming data on AWS that allows users to collect, process, and analyze real-time data streams.
c. Amazon EMR - A managed Hadoop framework that allows users to process large amounts of data using tools such as Spark, Hive, and HBase.
Google Cloud Platform (GCP) a. Cloud Dataflow - A fully managed service for building data pipelines that allows users to execute batch and stream processing jobs.
b. Cloud Pub/Sub - A messaging service that allows users to ingest and process real-time data streams.
c. Dataproc - A managed Hadoop and Spark service that allows users to process large amounts of data using open-source tools.
DBT
Few words on DBT…
DBT is a relatively recent data processing tool that is increasingly gaining popularity. Its main features are:
- It can be used with any of the cloud providers mentioned above as it integrates with many popular data warehouses, such as Snowflake, Redshift, and BigQuery, and can be used to build, test, and maintain data pipelines.
- It allows Analytics Engineers to define data transformations as code and build complex data pipelines that involve multiple steps.
- It can integrate with a variety of data analysis tools, including Python and R, allowing Analytics Engineers to extract insights from the data using statistical methods and machine learning algorithms.
- It defines data transformations in a standardized way, making it easy to ensure that data governance and security policies are applied consistently across all data pipelines.
In my opinion, this tool has the potential to become the one-stop-shop for the transformation layer and is a very important tool for Analytics Engineers to know.
Data Analysis
This is another step in the process where, in my opinion, Analytics Engineering has co-ownership with Data Analytics. In this case, data analysis shouldn’t be seen as the process of extracting valuable insights from the data. On the contrary, Analytics Engineering should leverage the business context provided by the DA part to ensure that the transformed data is of the highest quality and can be easily used by DAs to perform visualization tasks and/or advanced analytics.
Likely, an analytic engineer would need and want to use a mix of scripting languages that provide a high degree of freedom in exploring the data, as well as the BI tool used within the company, depending on the type of exploration, complexity, and adaptability of the BI tool and the skillset of the analytic engineer.
a. Scripting languages such as Python or R - Popular scripting/programming languages used for data analysis and machine learning. They have the advantage of having a plethora of libraries (and more are constantly added) that are open-sourced and maintained by the community.
b. Tableau/Looker/Power BI and similar tools - There are many data visualization tools out there that allow for the creation of interactive dashboards and reports. Depending on the complexity of the analysis and the adaptability of the tool, some of them might be valid resources for quick-n-dirty analysis.
Data Governance and Security
“Data protection, data privacy, and control of the data flow all fall under the Data Governance umbrella. This topic is becoming more and more relevant to Analytics practitioners, as indicated by recent increasing trends in Google search.
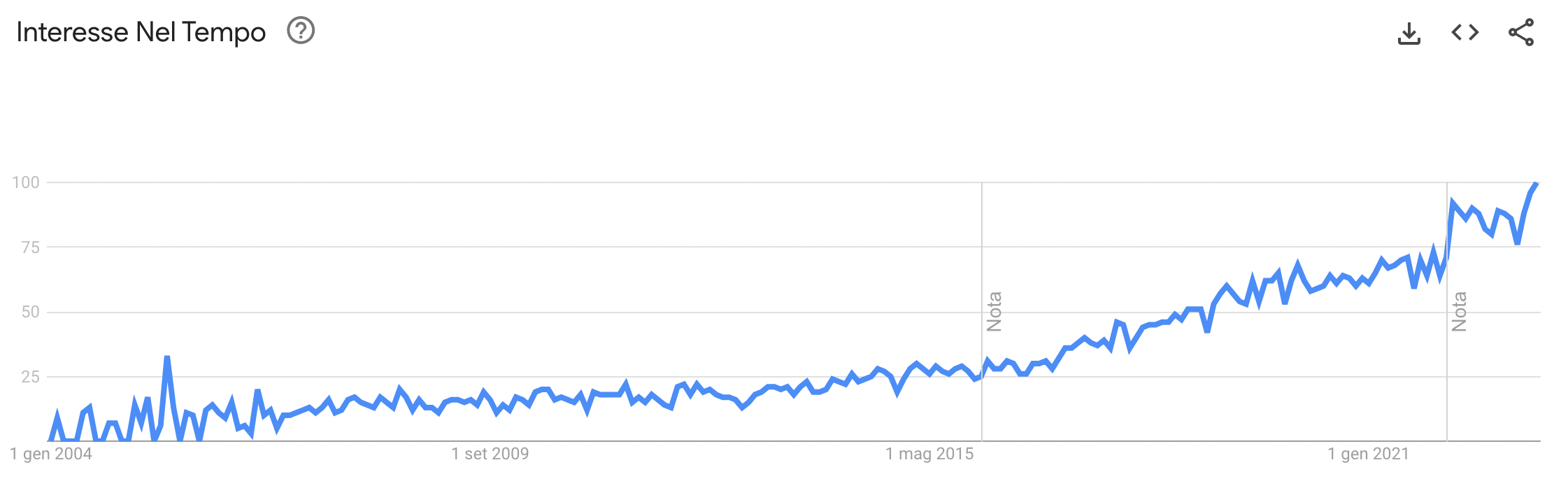 The trend of data governance since 2004
The trend of data governance since 2004
Data governance involves ensuring that data is accurate, reliable, and secure. As mentioned earlier, all mainstream cloud providers have one or more tools for managing data governance. Some popular examples include:
a. Apache Ranger - An open-source tool that provides centralized security administration for Hadoop.
b. Apache Atlas - An open-source tool that provides metadata management and governance for Hadoop.
c. AWS Identity and Access Management (IAM) - A cloud-based tool that provides access control and security management for AWS services.
Conclusion
I see a bright future for this sub-field within Analytics. I don’t know if the term Analytics Engineering will stick; however, it’s becoming increasingly difficult to think of the Data Engineer as the only person involved and responsible for managing data pipelines. I can see the benefit of having both separation of responsibilities on the transformation layer, as well as co-ownership of the Load and pure analytical layer.
Eventually, the Analytic Engineer will serve as an additional buffer between a very technical figure (the Data Engineer) and a more business-focused role (the Data Analyst/Scientist).